This post describes our CS109A final project at Harvard: a song recommender built with Spotify’s Million Playlist Dataset (MPD). The project was done together with Alpha Sanneh, Bella Gu, and Denise Yoon. A longer write-up and results are on our project website.
Many music streaming services let users create playlists—curated sets of songs that define a listening experience. A song recommender extends that experience by suggesting tracks that fit well with what’s already in the playlist. Our goal was to build such a system: given the songs in a playlist, recommend new songs that would make good additions, using the MPD.
Introduction
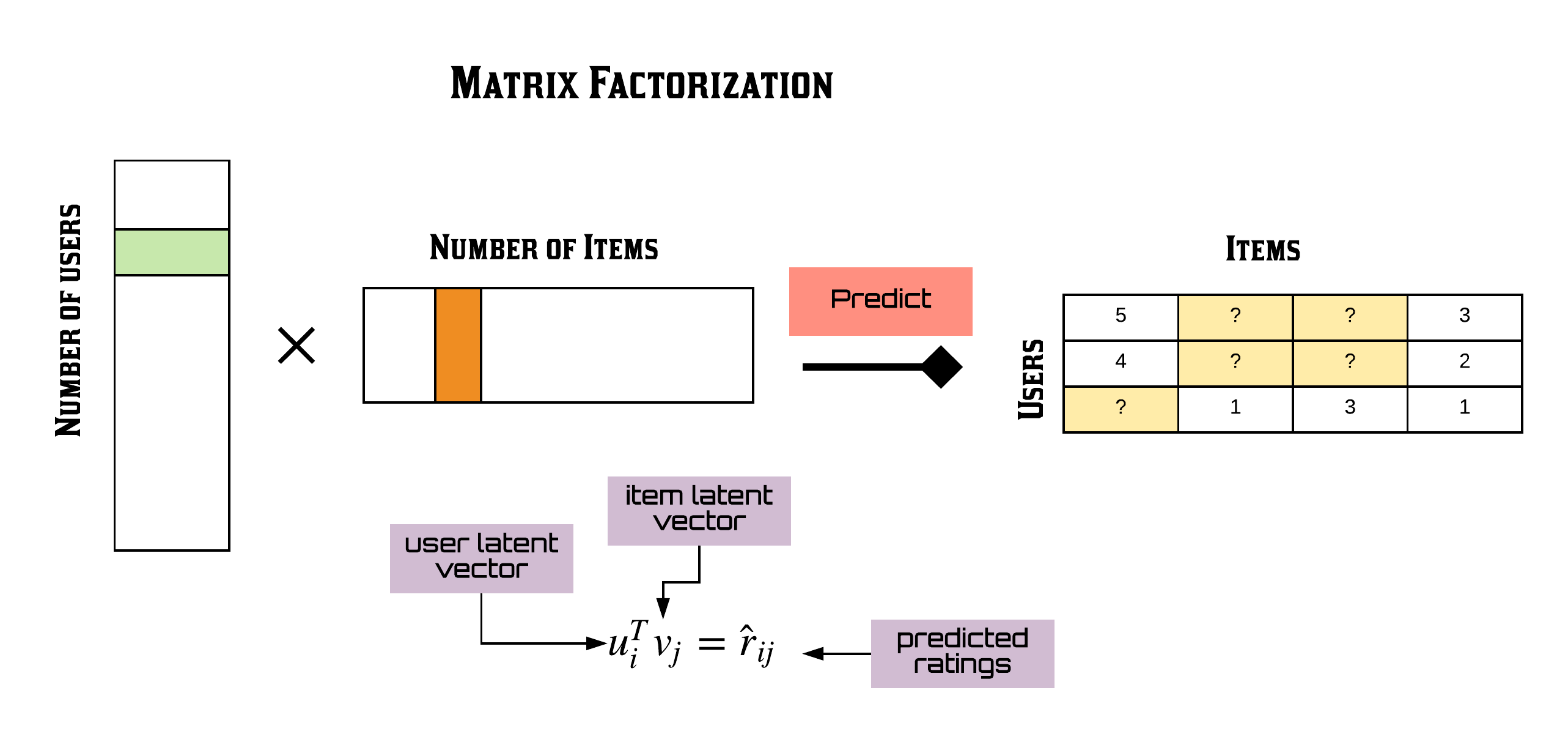
The Million Playlist Dataset contains millions of user-created playlists and the tracks within them. We used it to learn how songs co-occur across playlists and to predict which songs belong together. After an exploratory phase (including building a local SQLite database to query the ~12GB dataset), we focused on matrix factorization: we treat the data as a sparse playlist–song matrix and learn latent factors so we can fill in “missing” songs for a given playlist.
The model
We built a weighted matrix factorization model on a sparse playlist-by-song matrix. The idea is that both playlists and songs live in a lower-dimensional space; once we learn those embeddings, we can score any playlist–song pair and rank candidate songs for a playlist. The pipeline included:
- Sparse matrix construction — filtering rarely-seen songs and very short playlists to control sparsity
- Train–test split — holding out some playlist–song pairs for evaluation. We masked a certain percentage of interactions in the train set and revealed them in the test set to compare the real interactions to the interactions we predicted. Our validation set was the set of songs that were masked in the training set.
- Matrix factorization — fitting the model (we used ideas from implicit feedback recommenders and the implicit library)
- Hyperparameter tuning — grid search over key parameters
We also explored audio features from the Spotify API (e.g. for a cosine-similarity or item-based model) on a subset of the data; the main recommender is matrix factorization on the MPD.
Results
We evaluated recommendations on held-out data, e.g. how well we predict missing songs in a playlist. To evaluate our models' performances, we used precision@K which evaluates the proportion of K recommended items that are relevant to the user. In our case, this means what proportion of K recommended songs are actually present in the playlist. For all models, we chose to set K=10, meaning we recommended 10 songs for each playlist.
- Our popularity based model, which simply recommended the top 10 most popular songs in the dataset for every playlist, had a precision@K of 6.5% on the train set and 0.75% on the validation set.
- Constrained grid search to optimize alpha, factors, and regularization parameters gave us the best results, with a precision@K of 45.58% on the train set and 5.96% on the validation set. The performance improved a lot with our matrix factorization!
The write-up on our project website goes into more detail on metrics and examples.
Final thoughts
The project was a good exercise in working with a large, sparse dataset and in implementing a classic recommendation approach. Possible next steps we had in mind: more efficient hyperparameter search (e.g. Bayesian optimization), studying the effect of matrix sparsity on performance, and extending the engine to handle novel playlists or cold-start settings.